本文共 8840 字,大约阅读时间需要 29 分钟。
本文根据稻农在「Kubernetes \u0026amp; Cloud Native Meetup-广州站」现场演讲内容整理。
大家好,我的花名是稻农,首先我简单介绍一下我在这个领域的工作。在阿里,我们现在主要的侧重点是做大规模的运维和新的容器运行时。目前,大家可能已经对 Kubernetes 进行了广泛地使用,但多数还没有达到一定规模,有很多痛点以及内部的问题还没有得到充分暴露。本次分享将介绍阿里在大规模集群腾挪过程中遇到的有状态应用处理实践,以及在解决这些问题过程中应如何平衡成本和稳定性。
容器迁移背景及现状
目前,大多数容器的使用还在百台到千台的规模。我先简单介绍一下阿里目前内部容器服务。阿里的淘系应用如天猫、淘宝,目前已经全部实现了容器化,在集团的场景下面是没有虚拟机的。阿里用了大概三年到四年的时间,做到了 100% 容器化。
大家都知道使用容器有很多好处,比如它在资源耗费方面有很大优势。对于“双十一”大家应该有很明显地感受,相比之前,现在的“双十一”会“顺滑”很多,这样地转变也有容器化的功劳。
如果你有存量的业务,那你一定会面临从虚拟机或物理机迁移到容器的过程。绝大多数开发人员其实认为这是一个负担,因为他们的应用已经跑起来了,就不太希望因为基础设施地改变,去做更多工作去进行适配。所以出现了一些我们叫“富容器”或者“复杂应用容器”的特殊容器。
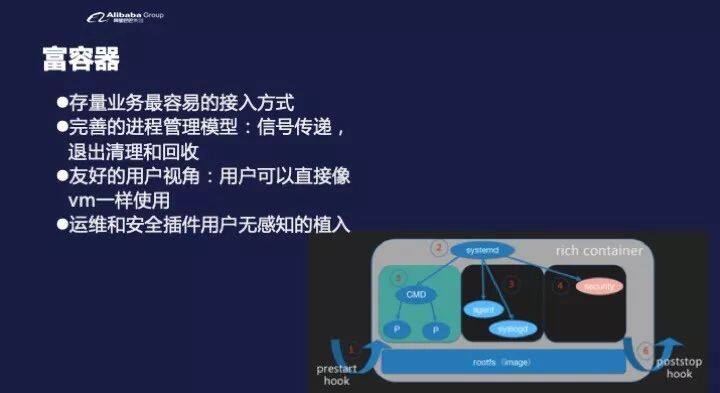
简单说,所谓富容器,就是我们回在容器内放置一些管理组件。阿里内部组件叫 star agent,它会提供登陆服务,提供各种各样的包管理,命令行的执行,诸如此类的事情。在真正运维和使用的过程中,整个容器与虚拟机的差别不大。
当然这个东西在业界是存在争议的,比如我们是不是应该先做微服务化,把所有服务都变成单一、不可改变的镜像再 run 起来,还是我们为了迁就一些技术债务引入富容器这种技术,这个地方是存在争议的。
但是可以告诉大家的是,如果你要完全按照理想化的微服务去执行,基本上很多大的应用(像淘系这些非常复杂的应用,改造一下可能要几个月)可能在第一步就被卡死了。因为我们有富容器,所以这个应用是有状态的,并不是随便说我砍掉他,然后异地重启就可以了,所以就是双刃剑的另一面,上线改造容易,运维变得复杂了。
我们有富容器的一些传统应用,很难对他们进行微服务无状态的改造,所以我们看到有很多场景,比如说容器出现故障时,开发或者运维的同学非常希望故障之后的新容器长得跟原来容器一模一样,比如 IP 、名字等任何东西都不变,非常符合他们的理想。
有时候,我们面对一些大规模的容器迁移,比如说在地方开一个很大的机房,我们就会把杭州或者是上海的容器全部迁走。在过程中非常麻烦的是有一些容器是有状态的,你迁的时候你还不敢动它,因为万一砍掉,可能红包就发不了了……
大的有状态的应用会占住物理机,造成没有办法去迁移。以上都是容器可携带状态迁移成为规模化运维的典型场景。

容器可携带状态迁移成为规模化运维难点在于 K8s 或者说整个容器与虚拟机的运维。Docker 公司曾给出说法,虚拟机像宠物一样,需要受到很精心地呵护才能永远活得很好,只要不好就需要去修它,这个就是宠物式的管理。K8s 认为容器应该是牛群式的放养,死了就直接重启而不需要对每一头牛做特别好地呵护,因为成本很高。
在 K8s 里面,我们经常看到的就是扩缩容,针对他的假设都是里面的应用是无状态。然后在执行层面,大家现在用的一般都是普通容器,或者说是标准容器引擎,就是 RunC,虽然 RunC 里面有个 checkpoint 和 restore 的机制,大家用起来就会发现基本上是不可用的,坑非常多。
容器可携带状态迁移成为规模化运维有两个难点,恰好是我们要解决的两个问题:
首先是管理面,K8s 上支撑 Pod 的迁移与伸缩不一样,我们所认为迁移就是这个容器要原封不动地在异地再重生;另外,我们认为冷迁移就是业务时间中断比较长,中断时间短的就是热迁移。那这个长短的分界岭在哪呢?
每个云厂商会有一些不同的看法。我们认为大概到毫秒级以下,一百毫秒或者十个毫秒这样的级别,可以认为它是热迁移。其实任何迁移基本上都会有业务中断的时间,任何一种机制去实现都不可能实现零时间切换。我们看一下 K8s 系统对整个容器迁移,2015 年开始,我们就讨论过 Pod 的迁移要不要放到 K8s 里面去,大家可以去翻 K8s 社区 issue,但一直没有下文。
其次在执行层面,RunC 作为容器运行时主流,虽有 CRIU 的项目辅助,仍然无法提供完善可靠的迁移机制。
管理面支撑 Pod 迁移
接下来,我们看看 K8s 为什么不能够做迁移?当前 K8s 系统的 Pod 迁移仍为空白。其中存在以下问题:

因为每个 Pod 有独立的标识,还有名字、ID 等。这个东西是要保证唯一性的,不然 K8s 自己也管理不了这些东西。假设有两个同学,他们的学号、名字长相完全一样,校长是要糊涂的。K8s 主推了对业务的伸缩,就是靠无状态伸缩,他不会把某一个容器从这迁到那去。
另外,K8s 骨干系统不支持 Pod 标识及 IP 冲突。我们认为 API server、schedule 这种必不可少的部分是骨干系统。几个骨干系统是不支持任何标识冲突的。如果有两个 Pod,他们 ID 一样, API server 就会糊涂,逻辑就会出问题。
K8s 是一套容器的管理系统,阿里周边对网盘 ID、对 IP,各种各样的资源,都有自己的管理系统。这些管理系统在 K8s 的世界里面,表现为不同的资源 controler,因为这些资源都是钱买来的,要跟底层账务系统联动,将来大家都会遇到这些问题,比如说这个部门是否有预算等。在阿里的 K8s 周边,我们已经开发了大量的这种 controler 了,他们都是按照这个标识,我们叫 SN 来管理应用的。数据库里面记录,每个容器都有一个的标识。
伸缩跟迁移是冲突。因为迁移的时候你可能需要砍掉旧容器。砍掉容器之后,伸缩控制如果正在生效(RC),它就会自动起一个新容器,而不是把这个容器迁移过去,所以这个地方我们对 RC 这些控制器都要做一定程度地改造。
其他问题,比如说很多远程盘不支持多 Mount。因为我们在做迁移的时候,这个盘一定要做到至少有两个 Mount。就是我的旧容器跟新容器,能够同时把 PV mount 上去,很多远程盘还是不支持的。
剩下还有一些传统底层支撑系统,比如 IP 管理系统不允许出现地址冲突。比如我们在分 IP 的时候分两个一样的是不可想象的,这个是我们最简单的迁移过程。迁移过程是这样的,我们想最小地去改造 K8s,当你的系统真正上了管理系统,复杂了以后,大家都会对 K8s 有一些适应性地改造。
这些改造最好的表现形式可能就是 controler 了,你不要去对骨干系统做改动,改动之后就很难再回到主线来了。在迁移过程中,我们还是没有办法一定要对骨干系统做一些改造,那么我们想尽量减少它的改造量。
第一步,我们会生成一个从资源上来讲跟原来的 Pod 或者容器完全一样的一个 Pod,它需要几核几 U,它需要一个什么远程盘,它需要一个什么的多少个 IP,多 IP 的话还要考虑多少个 IP,多少个直通网卡,或者是非直通的网卡,资源完全一样,这个是完全标准的。我们创建一个资源,一个新 Pod,这就像一个占位符一样。假设我这台物理机要坏了,那么我在一个打标之后,我在一个新的好的物理集群上,生产一个这样的 Pod,让我拿到了资源。
第二个过程就是说我们两边的 agent,比如说是 RunC 或者是阿里做的 pouch-container 也好,我们这种 OCI 的 Agent 之间会有一个协商的过程,它的协商过程就是会把旧的 Pod 的状态同步过去,刚才我们新生成的 Pod 镜像,实际它是占位符。
我们会把新的镜像动态地插入 Pod 里,API 对 CRI 的接口是支持的。当前,我们没有办法在一个已经产生的 Pod 里面去插入新的 container。但实际上 OCI 接口本身是支持的,可以在一个 sandbox 里面去删掉已有的 container 和增加新的 container,不需要做什么新的工作,只要打通管理层的事情就可以了。
另外,唤醒记忆的过程其实就是两边状态同步,状态同步完毕,我们会做一个切流,切流就是把旧的容器不再让新的需求过来,一旦我们监控到一个静默期,它没有新的需求过来,我们会把旧的 Pod 停掉。其实暂时不停掉也没关系,因为反正没有客户来找他进行服务了,已经被隔离到整个系统外面去了。删除资源是危险操作,一般会放置一两天,以备万一要回滚。
最后一个过程新开发工作量比较大,我们要把前面那个占位作用的 Pod 标识改掉,IP 与旧的设置成一样,然后一切需要同步的东西都在这一步完成。完成之后就上去通知 API server 说迁移过程完成,最后完成整个过程。所以大家会看到,其实第一步基本上标准的 K8s 就支持。

第二步我们是 K8s 不感知的,就是我们在两个宿主机上做两个 agent 做状态同步。对 K8s 的改造也比较小。那么最后一个会比较多,API server 肯定是要改。RC 控制器可能改,如果你有 CI 的这种就是 IPM 的管理,IPM 的管理,这个地方要改。
接下来,我从 OCI 的运行这个地方来来讨论这个过程,因为其实是有两层面,一个是我们篮框这里是一个 Pod,从它的状态 Dump 落盘到远端把它恢复,整个同步过程中,我们会插入对 K8s 系统的调用,涉及对容器管理系统的改造。
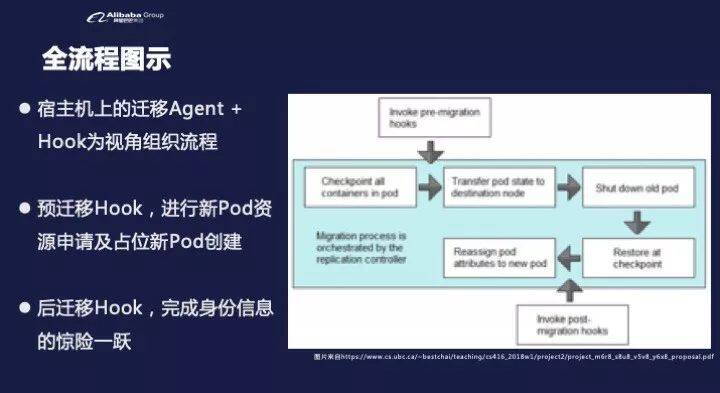
看外面这两个白框,上面这个我们叫预处理过程,其实就是前面讲的,我们要去创建新的 Pod、占位符,然后在那边把资源申请到最后一个后期建议。我们刚才说的最后一步,我们叫标识的重构重建跟旧的 Pod 完全一样。大家在我们开发过程中会遇到各种各样的冲突,如果 API server 有两个标识是一样的,这个代码就要特殊处理。APM 有时候会跳出来说你有 IP 冲突,这样也要特殊处理,至少有几个骨干系统肯定是要做的。
这部分因为涉及到 K8s 骨干的改造, patch 我们还没有提上来。接下来还要跟社区讨论他们要不要 follow 我们的做法,因为现在 K8s 的容器就是无状态的观点还比较占上风。
刚才我们讲到管理面我们认为是事务处理的,路上会有很多障碍,但是这些障碍都是可以搬掉的,就是说无非是这个东西不允许冲突,我改一改让他允许冲突,或者允许短时间的一个并存,那个东西不允许我再改一改。比较硬核的部分是底层引擎去支撑热迁移,尤其是热迁移,冷迁移其实问题不大,冷迁移就是说我只是恢复那些外部可见的状态(不迁移内存页表等内部数据),如果对我的业务恢复时间没有什么要求的话,就比较容易做。
RunC 引擎的可迁移性
RunC 应该是大家用的最多的,它就是标准的 container 去进行的迁移改造。如果大家去看过 checkpoint 开放的这部分代码,可以发现 RunC 依靠的机制就是一个叫 CRIU 的东西。CRIU 的优势技术已经出现比较长的时间了,用户态把一个进程或者一个进程数完全落盘在把它存到磁盘上,然后在异地从磁盘把进程恢复,包括它的 PC 指针,它的栈,它的各种各样的资源,经过一段时间地摸索,基本上可以认为内存状态是没有问题的,就是页表,页表是可以做到精确恢复的。

不管你这边涉及多少物理页是脏的,还是干净的,这个都是百分之百可以还原出来的。进程执行的上下文,比如各种寄存器,调用 stack 等,这些都没问题。跟纯进程执行态相关的问题都已经完全解决了,这个不用担心。然后大家比较担心的就是一个网络状态,比如说大家都知道 TCP 是带状态的,它是已连接?等待连接还是断开?其实这个网络 Socket 迁移的工作也基本完成了。
它的实现方法是在 Linux set 里面加了一个修复模式,修复模式一旦启动,就不再向外发送真正的数据包,而是只进行状态及内部 buffer 的同步,比如你下达的这种 close,不会向外发包,只是体现为对状态信息的导出。
比如说你要进入修复模式,那在原端就要关闭 Socket,它并不会真正的去发 close 的 TCP 包,它只是把信息 Dump 出来,在新的目的地端去 connect。它也不会真正去包,最后的结果就是除了 mac 地址不一样,TCP 里面的状态也恢复到远端了,里面的内存状态都转过去了,经过实际验证其实也是比较可靠。还有打开的文件句柄恢复,你打开的文件,你现在文件比如说读写指针到了 0xFF,文件的 off set 恢复都是没有问题的。
其实我们在冷热迁移中最担心的就是耗时问题,我一个容器究竟花多长时间?一个 Pod 多长时间可以迁移到新目的地的宿主机上去,耗时的就是内存。也就是说像很多 Java 应用,假设你的内存用得越多,你的迁移时间就是准备时间就越长。可以看到我们刚才其实是有一个协商过程。
在协商过程中旧的 Pod 还在继续提供服务,但是它会不停的把它的状态 Sync 到远端去。这个时间其实并不是业务中断的时间,如果耗时特别长,也会因为业务时在不停转的,如果你的内存总是在不停地做大量改动,你的准备时间和最后的完成时间就会非常长,有可能会超时。我们去评估一个业务能不能做热迁移,它所使用的内存大小是一个比较大的考量。
然后剩下就是我们踩到的坑。现在还有很多东西它支持的不大好。这个地方大家可以理解一个进程,一个进程其实就是一个自己的页表,有自己的堆栈,一个可执行的活体。那么它支持不好的部分都是外部的,如果它依赖一些主机设备,就很难把一个设备迁移走。接下来是文件锁,如果这个文件是多个进程共用就会加锁。因为这个锁的状态还涉及到别的进程,所以你只迁移这一个进程的时候会出问题。这个地方逻辑上会有问题,其实大家可以笼统地这样去判断,如果我依赖的东西是跟别的用户、进程有一些共享,甚至这个东西就是内核的一个什么设备,这种就比较难迁移走。所以简单来说就是自包含程度越高越容易迁移。
这个是一个比较详细的图,跟我刚才讲的过程其实是差不多,我们还是会在原端发起热迁移的请求,请求之后,会发起两端两边 Agent 的 sick,然后最后中间会切流。
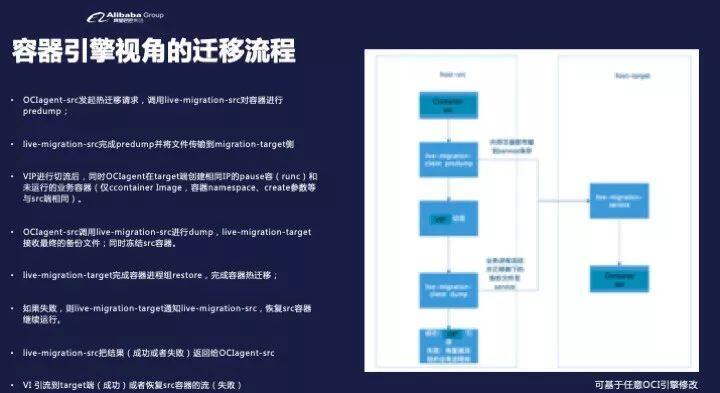
等到 Sync 状态完成,我们会通知 K8s 说我这边可以了,那么 K8s 会把流从旧的 Pod 切到新 Pod 来,然后最后把所有的标识与我的 SN 或 IP 都改造完了,最后通知一下 K8s 就结束了。
新运行时带来的机会
最后,我想分享的是新的运行时。我们在社区里面会看到容器,现在来说在私有云上,它的主要的形态还是 RunC,就是普通的 Linux 标准容器。我们在公有云上为了能混布,或者说跟内外客户在线离线都在一起,我们一般会选虚拟机类型的容器引擎,比如像 kata 这样的东西。
早先选择就只有两种,讲效率,不讲安全,就是纯容器;讲安全,不讲效率,就跑一个虚拟机式的容器。从去年开始,谷歌、亚马逊等头部玩家开始做一些新的事情,叫做进程级虚拟化。就像我们在中学物理讲过,比如说光的波粒二象性,它在一些维度上看起来是波,一些维度上是粒子。
其实这个与进程级虚拟化是很相像的,从资源管理这个角度看,它是一个普通进程。 但是在内部为了加强隔离性,会做一个自己的内核。从这个角度看,它是一个虚机;但是从外部资源角度来看,因为这个内核是隐形生效的(并没有动用其他虚拟机工具去启动容器),也不会去实现完整的设备级模拟,管理系统认为它就是一个普通进程。
这是一种新的潮流,也就是说我们判断这个东西(当然我们还需要在里面做很多工作)有可能会成为将来容器运行时的一个有益补充或者是主流。简单的说,这种新的运行时会有自己的私有内核,而且这个内核一般现在都不会再用 C 语言去再写一遍,因为底层语言比较繁琐,也很容易出错。
用过 C语言的人都知道带指针管理很危险,Linux 社区 bug 比比皆是,现代的做法都会用 Go 语言或其他一些高级语言重写,有自己的垃圾回收的机制,指针就不要自己去管理了。一般不会提供很丰富的虚拟设备管理。因为这部分对一个应用来说是冗余的,普通应用跑起来,其实很少去关心用什么设备需要什么特殊 proc 配置,简单的说就是把虚拟机的冗余部分全部砍掉,只留下普通应用 Linux 的 APP 跑起来。

这个是我们对运行史的一个简单的比较,是从自包含的角度来讲,因为自包含的程度越高,它的热迁移越容易实现,或一般来说安全性也越高。
亚马逊现在在做 Firecracker,它也是用现代语言重写了内核。微软的云也在做一个事情。大家的思路是比较一致的。因为硅谷技术交流是很频繁的,他们的技术人员之间都是比较知根知底的,谷歌做了 gVisor。
大家可能听说过谷歌的 gVisor,gVisor 是这样一个机制,就是说我会在一个 APP,就是普通的未经任何修改的 ,跑在容器里的 Linux 应用,那么我们怎么去让他用我们的内核而不用 Linux 内核?核心就是要捕获他的系统调用,或者说劫持都可以。
系统调用的劫持有软硬两种方法,软件来说,我们在 Linux 内核里面利用 pTrace 的机制,强迫就设完之后你设置的进程的所有系统调用,他不会让内核去,而是先到你进程来。这个叫做软件实现。
另一种方法我们叫硬件实现,就是说我们会强迫这个 APP 跑在虚拟机的状态。我们知道在虚拟机里面,虚拟机会有自己的中断向量表,它通过这种方式来获取执行时。然后我们的 Guest kernel 是这样的,我们会看到现在的类似内核是无比庞大的,截止到现在应该有 2000 万行代码,这里面绝大部分其实跟容器运行时没有太大关系。
所以我们现在想法就是只需要把 Syscall 服务作好,也就是说 APP 看到的无非就是这 300 多个 Syscall。这 300 多个系统调用你能够服务好,就是不管你的 Syscall 服务用 Go 写,还是用 Python 写的(不讲究效率的话)你都可以认为你有自己的内核,然后跟主机的内核是隔离的,因为我没有让 APP 直接接触主机内核的东西。
为了安全,我们也不允许用户直接去操作主机文件。 大家看到 RunC 上面像这样的你去操作的文件,事实上在主机上或者在宿主机上都是有一个代表,不管你 Overlay 出来,还是快照 DeviceMapper,你可以在磁盘上找到这个真实的存储。
其实这是一个很大的威胁,就是说用户可以直接去操作文件系统。他们操作文件系统之后,其实文件系统是有很多 bug 的。它代码量那么大,总是有可能突破的。所以我们加了防护层叫 Gofer。Gofer 是一个文件的代理进程,用户发出的所有 file 的 read 和 right 都会被我们截获,截获完会经过 Gofer 的审查。如果你确实有权限去碰这个文件,他才会去给你这个操作,这个是大概的一个架构。
然后简单讲一下 gVisor 里面是怎么跑的。APP 在 RunC 里面,它直接 call 到主机的内核。就是这条红线(下图),Call 这个内核,他该获得哪些 syscall 就会获得 syscall,如果假设内核是有什么故障或者 bug,这个时候它就可以突破一些限制。
在 gvisor 的里面,他的执行方是这样的,我的 APP 第一步会被 PTrace 或者我的 KVM-Guest 内核捕获,捕获之后在我们叫 Sentry,为什么这个红线画的划到 kernel 上面,因为捕获的过程,要么是经过 KVM-Guest-ring0 的,要么是经过 PTrace 系统调用,所以我认为还是要内核帮忙。然后 sEntry 拿到这个系统调用之后,它会去做力所能及的事情,比如说你要去读一些 PROC 文件,你要去申请文件句柄,本地就可以完成服务返回,这是非常高效的。
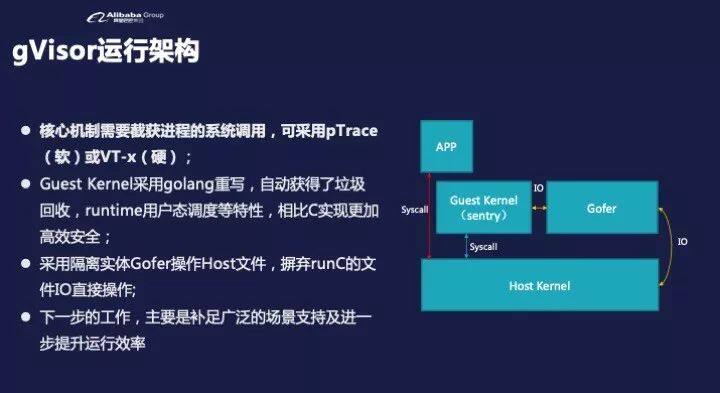
然后有一些事情,假如你要去读写主机上的一个网卡,sEentry 自己确实做不了,它就会把这个需求转发到主机内核上去,等得到服务之后再原路返回。文件操作就是这样的,如果读写任何的主机文件,都会去 Call 到 Gofer 的进程(审查请求),然后代理访问服务,去读写真正的文件把结果返回。这个是大家可以看到,APP 就是被关在两重牢笼里:一个是 Guest Kernel(sentry);一个是 Host Kernel。因为它本身又是一个进程,所以从安全性上来讲 APP 和 sEntry 不共页表,其实可以说比虚拟机还要安全。
因为虚拟机里面 Guest Kernel 与 APP 共页表,Guest Kernel 躲在这个列表的上端。而在 gVisor 里面 Guest Kernel 跟 APP 是完全不同的两套页表,诸如此类有很多方面,大家会发现 gVisor 比虚拟机更加安全。
当然我们做了这么多隔离,也会有副作用,就是运行效率会有问题,尤其是网络,我们都会持续改进,把虚拟机已有的一些经验用到 Go 的内核上去,我们的理想是虚拟损耗低于 5%。

未来,大家可以去比较各种运行时。当我们选型一个容器的引擎,会去综合地看它的运行效率,它的安全性,尤其是代码复杂度,代码越多,基本上你可以认为这个东西出 bug 的几率就越高,代码越少其实越好。
我们跟业界还有一个合作,另外我们还在想做对容器运行时做一个测评,最后综合打一个分。完成后会开源给大家使用。怎么去评价一个 Runtime 是好的,是高效的,它的安全性到多少分?就跟汽车的这种评分一样的。我今天介绍大概就是这些。
转载地址:http://dsesx.baihongyu.com/